
[INQ. NO. 2305E02] STV is an advanced version of Text-To-Video (TTV) that automatically converts text into video. As an artificial intelligence (AI) software, it analyzes voice data to extract text, summarizes the extracted data into key sentences, and calculates keywords derived through machine learning to match images, videos, and sound sources.


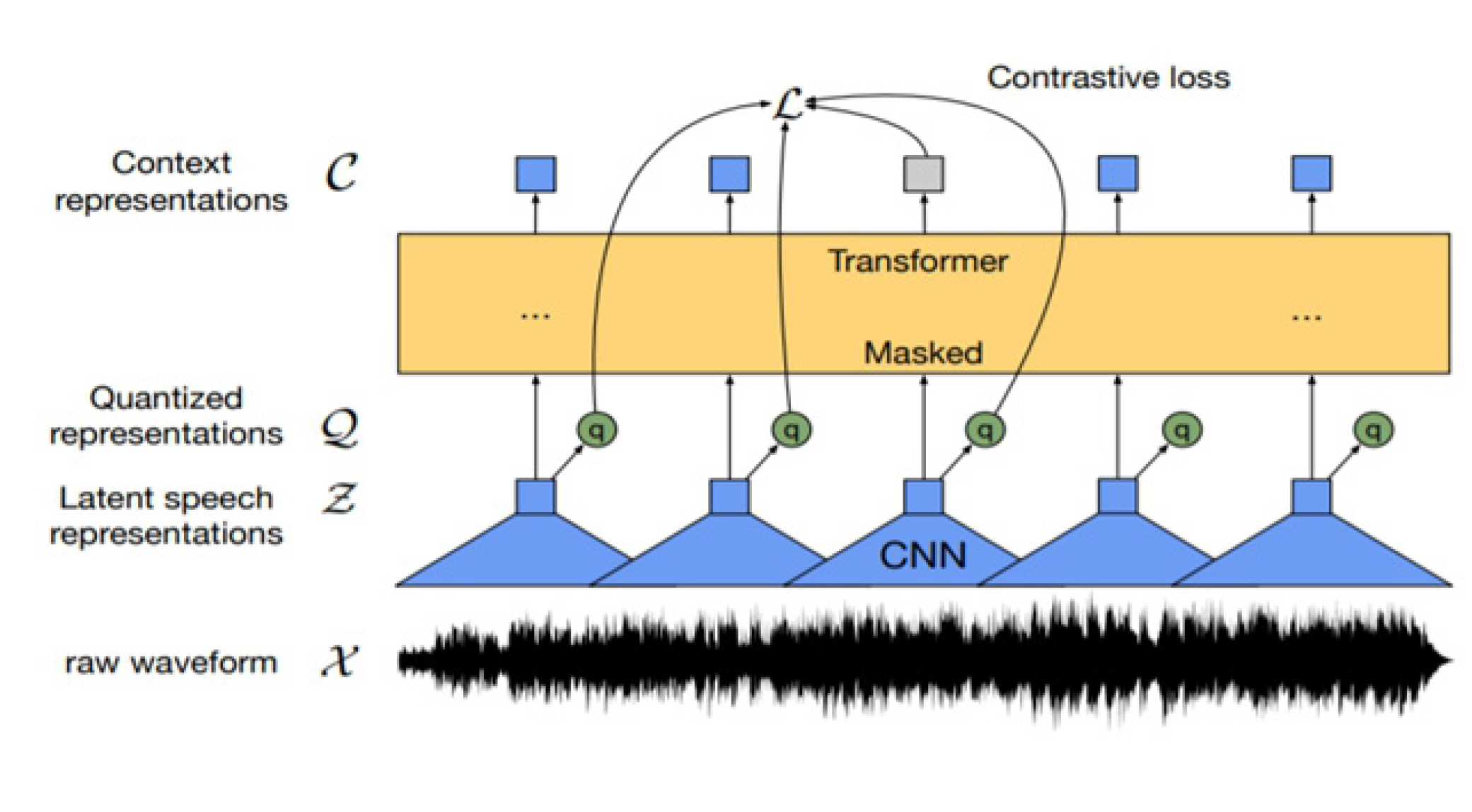
Wayne Hills Bryant AI’s Speech-To-Text (STT) performs Masked Language Modeling (MLM) and Connectionist Temporal Classification (CTC) simultaneously. It masks a part of voice data, predicts and learns it, and creates a context expression that restores the masked part through surrounding information. In this way, voice data is converted into text using artificial intelligence.
Based on the converted text data, AI, based on machine learning (ML) and natural language processing (NLP), summarizes the text’s plot and automatically converts it into a video by combining video, sound sources, and images.
The software’s use is versatile, ranging from B2C users who produce daily videos lightly, to B2B which converts recordings of lectures and meetings into various promotional/educational materials, and B2G which turns reports and plans into images.
A spokesperson for the company said, “We won the CES Innovation Award last year and were recognized as a company with outstanding technology that has the potential to become a unicorn company in the future. We hope that our solutions, such as TTV and STV, can help prospective founders and companies with outstanding ideas to create services that reach out to the world.”
korean-electronics.com | Blog Magazine of korean electronics, brands and Goods




Leave a comment